JDK08 在语言层面的重大更新主要为函数式编程,掌握函数式编程有诸多好处:
- 大数量下处理集合效率高
- 代码可读性高
- 消灭嵌套地狱
- 理解并读懂公司利用这部分功能特性编写的代码,能读懂优秀开源项目代码
举个栗子:找出年龄大于38岁的作家的所有评分超过85分的书籍集合,要求结果不能重复。
JDK07:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void test01() {
List<Book> bookList = new ArrayList<>();
Set<Book> uniqueBooks = new HashSet<>();
Set<Author> uniqueAuthors = new HashSet<>();
for (Author author : authors) {
if (author.getAge() < 38) {
continue;
}
if (uniqueAuthors.add(author)) {
List<Book> books = author.getBooks();
for (Book book : books) {
if (book.getScore() > 85) {
if (uniqueBooks.add(book)) {
bookList.add(book);
}
}
}
}
}
}JDK08:
1
2
3
4
5
6
7
8
9
10
11
void test02() {
List<Book> list = authors.stream()
.distinct()
.filter(author -> author.getAge() > 38)
.map(Author::getBooks)// method reference
.flatMap(Collection::stream)// method reference
.filter(book -> book.getScore() > 85)
.distinct()
.collect(Collectors.toList());
}
代码可读性有显著的提升,也消除了多层嵌套。
JDK08 函数式编程特性的诞生使得编写代码时思维函数式编程化,将函数式编程思想对比面向对象思想对比:
- 面向对象思想关注的是用什么对象做什么样的事情。
- 函数式编程思想类似于数学中的函数,主要关注对数据进行了什么操作。
- 函数式编程思想有着以下有点:
- 代码简洁
- 编码效率高
- 接近自然语言易于理解
- 易于并发编程
Lambda
Lambda Expression 是 JDK08 中的语法糖,可以对某些匿名内部类的写法进行简化;它是函数式编程思想的一个
重要体现,让使用者不用关注是什么对象,将焦点置于对数据进行了什么操作。
核心原则
可推导,可省略。
语法格式
1 | (args) -> { |
其语法格式主要强调:参数和过程,即使用传入的参数做了什么事情;同时省略了类名,因此掌握该特性的关键不是去记各种类名,而是着重关注入参和过程代码操作。
实际执行时调用的是类的什么方法,JDK 通过方法参数自行推断,体现了其可推导性。
栗子1:分别使用匿名内部类和 Lambda 表达式调用创建线程。
1
2
3
4
5
6
7
8
9/*
with lambda
*/
new Thread(new Runnable() {
public void run() {
System.out.println("Thread.run1");
}
}).start();1
2
3
4
5/*
without lambda
*/
new Thread(() -> System.out.println("Thread.run2")).start();
new Thread(() -> System.out.println("Thread.run3"), "thread-new").start();栗子2:现有方法定义如下(
IntBinaryOperator是一个接口)。1
2
3private int calculate(int left, int right, IntBinaryOperator operator) {
return operator.applyAsInt(left, right);
}分别使用匿名内部类和 Lambda 表达式调用该方法:
1
2
3
4
5
6
7
8
9/*
without lambda
*/
int i1 = calculate(10, 20, new IntBinaryOperator() {
public int applyAsInt(int left, int right) {
return left + right;
}
});1
2
3
4
5/*
with lambda
*/
int i2 = calculate(10, 20, (left, right) -> left + right);
int i3 = calculate(10, 20, Integer::sum);// method reference栗子3:现有方法定义如下(
IntPredicate是一个接口)。1
2
3
4
5
6
7
8
9private void printArrayMemberByPredicate(int[] arr, IntPredicate predicate) {
if (Objects.nonNull(arr) && arr.length != 0 && Objects.nonNull(predicate)) {
for (int i : arr) {
if (predicate.test(i)) {
System.out.println(i);
}
}
}
}分别使用匿名内部类和 Lambda 表达式调用该方法:
1
2
3
4
5
6
7
8
9/*
without lambda
*/
printArrayMemberByPredicate(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, new IntPredicate() {
public boolean test(int value) {
return value % 2 == 0;
}
});1
2
3
4/*
with lambda
*/
printArrayMemberByPredicate(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, i -> i % 2 == 0);栗子4:现有方法定义如下(
Function是一个接口)。1
2
3private <T, R> R convert(T t, Function<T, R> f) {
return f.apply(t);
}分别使用匿名内部类和 Lambda 表达式调用该方法:
1
2
3
4
5
6
7
8
9/*
without lambda
*/
Integer i1 = convert("9527", new Function<String, Integer>() {
public Integer apply(String str) {
return Integer.valueOf(str);
}
});1
2
3
4
5/*
with lambda
*/
Integer i2 = convert("9527", str -> Integer.valueOf(str));
Integer i3 = convert("9527", Integer::valueOf);// method reference栗子5:现有方法定义如下(
IntConsumer是一个接口)。1
2
3
4
5
6
7
8private void intArrayForeachConsume(int[] arr, IntConsumer consumer) {
if (Objects.isNull(arr)) {
return;
}
for (int i : arr) {
consumer.accept(i);
}
}分别使用匿名内部类和 Lambda 表达式调用该方法:
1
2
3
4
5
6
7
8
9/*
without lambda
*/
intArrayForeachConsume(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, new IntConsumer() {
public void accept(int value) {
System.out.println(value);
}
});1
2
3
4
5/*
with lambda
*/
intArrayForeachConsume(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, i -> System.out.println(i));
intArrayForeachConsume(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, System.out::println);// method reference
省略规则
参数类型可以省略(不用过度关注于类)。
方法体只有单行代码时,代码块的大括号、
return关键字、单行代码的分号;均可省略。
即代码:1
2
3(args) -> {
retrun 0;
}省略为:
1
(args) -> 0
方法的参数列表只有单个参数时,小括号
()可省略。
即代码:1
(args) -> 0
省略为:
1
args -> 0
Stream
JDK08 的 Stream 使用的是函数式编程模式,如同它的名字一样,它可以被用来对集合或数组进行链状流式的操作;使用 Stream 可以更方便的对集合或数组进行操作。
注意事项
- JDK08 提供了对象流和基本类型流:
Stream类用于处理对象流IntStream、LongStream、DoubleStream分别是用于处理int、long、double的流;除此之外,无其他基本数据类型的流。
- 流与集合对比有以下不同之处:
- 没有存储:流不是存储元素的数据结构; 它将源数据(如,数据结构、数组、生成器函数、I/O channel)在多个计算操作的管道中传递。
- 功能性质:对流的操作会产生结果,但是不会修改流的源数据;如,对集合流进行过滤会得到一个新的不包含被过滤掉的元素的流(流是一次性的),而不是从流的源数据中删除被过滤元素。
- 懒惰求值:大量的流操作,诸如,过滤,转换,去重可以惰性的实现,从而暴露优化的机会;比如:从
1到10中获取前3个最小的数,不需要检查所有的数,流的操作可以分为:- 中间操作:中间操作总是惰性求值。
- 终结操作
- 可无限性:集合的大小是有限的,而流可以是无限的;流的短路操作,如:
limit(n),findFirst()可以允许在无限流上的计算在有限的时间内完成。 - 可消费性:流的元素在其生命周期中只能被访问一次,这点和集合的
Iterator相似;必须生成一个新的流来重新访问源的相同元素。
案例模型
本节所有案例中使用的对象模型、测试数据代码如下:
对象模型:
Book:1
2
3
4
5
6
7
8
9
10
11
public class Book {
private Long id;
private String name;
private Double score;
private String category;
private String introduction;
}Author:1
2
3
4
5
6
7
8
9
10
11
public class Author {
private Long id;
private Integer age;
private String name;
private List<Book> books;
private String introduction;
}
测试基类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243public abstract class Preparation {
private final PrintStream out = System.out;
private final PrintStream err = System.err;
protected List<Author> authors = new ArrayList<>();
protected final ByteArrayOutputStream bout = new ByteArrayOutputStream();
protected final ByteArrayOutputStream berr = new ByteArrayOutputStream();
void prepare() {
prepareSomething();// 初始化数据
prepareAssertSystemStreams();// 初始化控制台输出流断言环境
}
private void prepareSomething() {
/*--------------------------------- books ---------------------------------*/
// books of marx when he was 35
List<Book> marx35books = new ArrayList<>(Arrays.asList(
Book.builder()
.id(10L)
.name("资本论")
.score(99.99)
.category("社会,文学")
.introduction("这部巨著第一次深刻地分析了资本主义的全部发展过程,阐述了资本主义商品生产、流通和分配的基本理论,揭示了经济发展的客观规律,具有划时代的历史意义。")
.build(),
Book.builder()
.id(11L)
.name("共产党宣言")
.score(88.01)
.category("文学")
.introduction("《共产党宣言》是马克思和恩格斯为共产主义者同盟起草的纲领,是国际共产主义运动的第一个纲领性文献,这部著作的问世标志着马克思主义的诞生。")
.build(),
Book.builder()
.id(12L)
.name("1844年经济学哲学手稿")
.score(85.31)
.category("经济")
.introduction("对涉及哲学、政治经济学和共产主义理论的各种历史文献和思想观点进行系统研究和批判的最初成果。")
.build(),
Book.builder()
.id(13L)
.name("法兰西内战")
.score(89.60)
.category("政治")
.introduction("本书分析了巴黎公社的发展过程和历史意义,概括了公社的历史经验发展了马克思主义关于无产阶级革命和无产阶级专政的学说,特别是用巴黎公社的新经验进一步论证和丰富了无产阶级革命必须首先打碎资产阶级国家机器的思想。")
.build()
));
// books of marx when he was 60
List<Book> marx60books = new ArrayList<>(Arrays.asList(
Book.builder()
.id(14L)
.name("德意志意识形态")
.score(95.49)
.category("社会")
.introduction("论述了共产主义和无产阶级革命的理论。")
.build(),
Book.builder()
.id(15L)
.name("关于费尔巴哈的提纲")
.score(83.90)
.category("社会,政治")
.introduction("批判费尔巴哈直观的、抽象的旧唯物主义,为确立革命的,批判的,实践的新唯物主义扫清障碍。")
.build(),
Book.builder()
.id(16L)
.name("剩余价值理论")
.score(85.31)
.category("经济")
.introduction("马克思的剩余价值理论是在批判地继承古典政治终济学的研究成果和他所创立的科学的劳动价值理论的基础上,经过长期的考察和研究逐步建立起来的。")
.build()
));
// books of lao shaw when he was 35
List<Book> laoshaw35books = new ArrayList<>(Arrays.asList(
Book.builder()
.id(17L)
.name("断魂枪")
.score(94.50)
.category("小说")
.introduction("该小说情节简单,讲述了沙子龙这一武林高手改变身份当客栈老板后的境遇,串连王三胜卖艺、孙老者与王三胜比武、孙老者献技三个小片段。")
.build(),
Book.builder()
.id(18L)
.name("牛天赐传")
.score(84.90)
.category("小说")
.introduction("小说写一对牛姓夫妇收养了一个在其门口被发现的小孩子,这个孩子是老天爷给的,就叫牛天赐。天赐什么都不会做,养父母一死,他就玩完了。怎么办……")
.build(),
Book.builder()
.id(19L)
.name("且说屋里")
.score(85.31)
.category("小说")
.introduction("这篇是写一个卖国贼包善卿在学生运动下的恐慌,而他的长女是带头反对他,打倒他的一员。像一个残篇。")
.build()
));
// books of lao shaw when he was 40
List<Book> laoshaw40books = new ArrayList<>(Arrays.asList(
Book.builder()
.id(20L)
.name("骆驼祥子")
.score(96.20)
.category("小说,文学")
.introduction("《骆驼祥子》以旧北平为背景,描写了一个外号“骆驼”名叫祥子的人力车夫的悲惨遭遇,反映了生活在城市最底层的广大劳动人民的痛苦,暴露了旧社会的罪恶。")
.build(),
Book.builder()
.id(21L)
.name("幽默的生活家")
.score(89.11)
.category("散文")
.introduction("本书精选老舍散文57篇,有游记闲谈,有生活小品,有人事回忆,或写景谈人或论事,无一不有情、有趣。")
.build(),
Book.builder()
.id(22L)
.name("茶馆")
.score(94.40)
.category("话剧")
.introduction("一个叫裕泰的茶馆揭示了近半个世纪中国社会的黑暗腐败、光怪陆离,以及在这个社会中的芸芸众生。")
.build()
));
// books of lao shaw when he was 63
List<Book> laoshaw63books = new ArrayList<>(Arrays.asList(
Book.builder()
.id(23L)
.name("猫城记")
.score(85.00)
.category("小说,文学")
.introduction("《猫城记》是老舍所著具有讽喻及科幻色彩的长篇小说。该书采用游记式的结构展开故事,用第一人称写作,以“我”飞离地球开始,以“我”返回地球结束,描述了“我”在猫国经历了一番奇遇")
.build(),
Book.builder()
.id(24L)
.name("离婚")
.score(86.23)
.category("小说")
.introduction("一个旧衙门里的小职员老李,有能力、做事认真,对社会有着隐隐的批判精神,但是性格懦弱。他不满意自己的婚姻,可是却没有勇气摆脱;心中的那份“诗意”在扰动着他,让他有一丝渴望、一点幻想")
.build()
));
laoshaw63books.addAll(laoshaw35books);
laoshaw63books.addAll(laoshaw40books);
// books of haruki when he was 49
List<Book> haruki49books = new ArrayList<>(Arrays.asList(
Book.builder()
.id(25L)
.name("海边的卡夫卡")
.score(76.01)
.category("小说,文学")
.introduction("海边的卡夫卡》叙述了一个十五岁离家少年与一个名叫中田聪的人的经历,两个角色作两条线索来写,而且两人自始至终未曾相遇。")
.build(),
Book.builder()
.id(26L)
.name("挪威的森林")
.score(79.31)
.category("小说")
.introduction("小说以主人公渡边为叙述视角,更多注重精神方面的感受。渡边的第一个爱人叫直子,是他高中时候好同学木月的女友。木月自杀一年后,渡边同直子相遇,然后开始交往。直子现在变得安静娴雅,美丽的眼睛里偶尔会掠过一丝阴翳。两人的恋爱就是在落叶飘零的东京街头漫无目的地行走,或前或后或者并肩。直子20岁生日的那个晚上,两人发生了关系,第二天渡边醒来,直子已踪影全无。几个月后,直子来信,说她住进了一家深山里的精神疗养院。")
.build()
));
/*--------------------------------- authors ---------------------------------*/
Author marx35 = Author.builder()
.id(1L)
.age(35)
.name("卡尔·马克思")
.books(marx35books)
.introduction("马克思主义的创始人之一,第一国际的组织者和领导者,马克思主义政党的缔造者之一,全世界无产阶级和劳动人民的革命导师,无产阶级的精神领袖,国际共产主义运动的开创者。")
.build();
Author marx60 = Author.builder()
.id(2L)
.age(60)
.name("卡尔·马克思")
.books(marx60books)
.introduction("马克思主义的创始人之一,第一国际的组织者和领导者,马克思主义政党的缔造者之一,全世界无产阶级和劳动人民的革命导师,无产阶级的精神领袖,国际共产主义运动的开创者。")
.build();
Author laoshaw30 = Author.builder()
.id(3L)
.age(30)
.name("老舍")
.books(laoshaw35books)
.introduction("老舍的一生,总是忘我地工作,他是文艺界当之无愧的“劳动模范”。")
.build();
Author laoshaw66 = Author.builder()
.id(4L)
.age(66)
.name("老舍")
.books(laoshaw40books)
.introduction("老舍的一生,总是忘我地工作,他是文艺界当之无愧的“劳动模范”。")
.build();
Author laoshaw71 = Author.builder()
.id(5L)
.age(71)
.name("老舍")
.books(laoshaw63books)
.introduction("老舍的一生,总是忘我地工作,他是文艺界当之无愧的“劳动模范”。")
.build();
Author haruki49 = Author.builder()
.id(6L)
.age(49)
.name("村上春树")
.books(haruki49books)
.introduction("村上春树是用一种清澈、朴实的日本风格写作的。他被译成外语,受到广泛阅读,尤其是在美国、英国和中国。他是以三岛由纪夫和我本人做不到的某种方式在国际文坛为他自己创造了一个位置。")
.build();
authors.add(marx35);
authors.add(marx60);
authors.add(laoshaw30);
authors.add(laoshaw66);
authors.add(laoshaw71);
authors.add(haruki49);
authors.add(haruki49);
}
private void prepareAssertSystemStreams() {
System.setOut(new PrintStream(bout));
System.setErr(new PrintStream(berr));
}
protected void restoreInitialSystemStreams() {
if (Objects.equals(out, System.out) || Objects.equals(err, System.err)) {
return;
}
System.setOut(out);
System.setErr(err);
}
}
入门栗子
需求:输出所有年龄小于
35岁的作家的名字并去重。实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class StreamHelloWorldChestnutTest extends Preparation {
/**
* 输出所有年龄小于35岁的作家的名字并去重。
*/
void test01() {
authors.stream()
.filter(author -> author.getAge() < 35)
.map(Author::getName)// method reference
.distinct()
.forEach(System.out::println);// method reference
Assertions.assertEquals(
1,
bout.toString()
.split(System.lineSeparator())
.length
);
}
}
常用操作
本节将通过一连串的例子由浅入深来使用 Stream 的相关 API,Stream 的常用操作 API 大纲如下:
流的创建
单列集合创建流:
Collection接口的相关实现类通过实例的.stream()方法为其创建流。1
2
3
4
5
6
7
8
9
10/**
* 单列集合创建流
*/
void test01() {
List<Object> list = new ArrayList<>();
Stream<Object> listStream = list.stream();
Set<Object> set = new HashSet<>();
Stream<Object> setStream = set.stream();
}数组如何创建流:
Arrays.stream(T[] array),该方法有多个基本类型数组参数的重载。1
2
3
4
5
6
7
8
9
10
11
12/**
* 数组如何创建流
*/
void test02() {
int[] intArr = {};// primitive data types array
IntStream intStream = Arrays.stream(intArr);// will create primitive data types stream
Object[] objArr = {};
Stream<Object> objStream = Arrays.stream(objArr);
Integer[] integerArr = {};
Stream<Integer> integerStream1 = Arrays.stream(integerArr);
}双列集合创建流:
Map接口的相关实现类需要先将其转为单列集合,再通过单列集合实例的.stream()方法为其创建流。1
2
3
4
5
6
7
8
9
10/**
* 双列集合创建流
*/
void test03() {
Map<String, Object> map = new HashMap<>();
Stream<String> strStream = map.keySet().stream();// key stream
Stream<Object> objStream = map.values().stream();// val stream
Stream<Map.Entry<String, Object>> entryStream = map.entrySet().stream();// key-val entries set stream
}创建文件内容流:
BufferedReader.lines()、Files.lines(Path path),后者是对前者大量代码的封装。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43/**
* 创建文件内容流
*/
void test04() {
String filePathName = "." + File.separator + "words.txt";
String[] words = new String[]{"风景优美", "迷人的", "美如画", "dazing", "breathtaking"};
try (
FileOutputStream fos = new FileOutputStream(filePathName);
OutputStreamWriter ows = new OutputStreamWriter(fos);
BufferedWriter writer = new BufferedWriter(ows)
) {
for (String word : words) {
writer.append(word).append(System.lineSeparator());
}
writer.flush();
} catch (IOException e) {
System.out.println(e.getMessage());
}
try (
FileInputStream fis = new FileInputStream(filePathName);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader reader = new BufferedReader(isr)
) {
reader.lines().forEach(System.out::println);
} catch (IOException e) {
System.out.println(e.getMessage());
}
/*
Files.lines()方法是对上面的代码的封装方法。
*/
try (Stream<String> lines = Files.lines(new File(filePathName).toPath())) {
lines.forEach(System.out::println);
} catch (IOException e) {
System.out.println(e.getMessage());
}
}创建文件路径流:
Files.list(Path dir)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/**
* 创建文件路径流
*/
void test05() {
String home = System.getProperty("user.home");
/*
将输出当前用户目录下的所有文件夹和文件的路径
*/
try (Stream<Path> list = Files.list(new File(home).toPath())) {
list.forEach(path -> System.out.println(path.toString()));
} catch (IOException e) {
System.out.println(e.getMessage());
}
}创建随机数的流:
1
2
3
4
5
6
7
8
9
10/**
* 创建随机数的流
*/
void test06() {
Random random = new Random();
IntStream ints = random.ints();
LongStream longs = random.longs();
DoubleStream doubles = random.doubles();
}静态方法创建流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52/**
* 静态方法创建流
*/
void test07() {
/*
Stream.of(T t)
Stream.of(T... t)
*/
int[] integers = {};
Stream<int[]> stream1 = Stream.of(integers);// Stream.of(T t)
Double[] doubles = {};
Stream<Double> stream2 = Stream.of(doubles);// Stream.of(T... t)
/*
IntStream.range(int startInclusive,int endExclusive)
LongStream.range(int startInclusive,int endExclusive)
*/
IntStream.range(0, 10).forEach(System.out::println);// 左闭右开,输出0至9
LongStream.range(0, 10).forEach(System.out::println);// 左闭右开,输出0至9
Stream<Long> longs = Stream.iterate(0L, l -> Long.sum(l, 1));// 创建无限流,每次自增1
longs.limit(5).forEach(System.out::println);//输出前5个
/*
IntStream.rangeClosed(int startInclusive,int endInclusive)
LongStream.rangeClosed(int startInclusive,int endInclusive)
*/
IntStream intStream1 = IntStream.rangeClosed(0, 10); // 左闭右开,0至9
IntStream intStream2 = IntStream.rangeClosed(10, 20); // 左闭右开,10至19
Stream<Integer> integerStream1 = intStream1.boxed();
Stream<Integer> integerStream2 = intStream2.boxed();
/*
Stream.concat(Stream<? extends T> s1,Stream<? extends T> s2) 连接两个流
*/
Stream.concat(integerStream1, integerStream2).forEach(System.out::println);
/*
Stream.empty() 空流
*/
Stream.empty().forEach(System.out::println);
/*
Stream.generate(Supplier<T> s) 生成流,使用给定的值供应函数生成一个无序的无限流
*/
Stream.generate(System::currentTimeMillis).limit(10).forEach(System.out::println);
}其他方式创建流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46/**
* 其他方式创建流
*/
void test08() {
/*
BitSet.stream()
*/
BitSet bs = new BitSet(16);
for (int i = 0; i < 16; i++) {
if ((i % 2) == 0) bs.set(i);
}
bs.stream().forEach(System.out::println);
/*
分隔符正则表达式将字符串分隔为流
*/
Pattern.compile(",").splitAsStream("小红,小黑,小白").forEach(System.out::println);
/*
JarFile.stream() Jar文件流
*/
String pathname = String.join(
File.separator,
System.getProperty("user.home"),
".m2",
"repository",
"mysql",
"mysql-connector-java",
"8.0.29",
"mysql-connector-java-8.0.29.jar"
);
File file = new File(pathname);
try (JarFile jar = new JarFile(file)) {
jar.stream().forEach(jarEntry -> {
System.out.println(jarEntry.getName());// 将输出jar中所有.class文件的名称,如:com/mysql/cj/jdbc/exceptions/SQLError.class
});
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
中间操作
peek:该方法是 JDK08 提供的用于调试流的最佳方式。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/**
* peek
* <p>
* 该方法是 JDK 08中最佳的用于调试流的方法
*/
void testPeek() {
authors.stream()
.peek(author -> System.out.println(author.getId()))
.forEach(author -> System.out.println(author.getName()));
String console = bout.toString();
Assertions.assertTrue(console.contains("5"));// 断言控制台中输出的作家id包含5
Assertions.assertTrue(console.contains("老舍"));// 断言控制台中输出的作家名称包含老舍
restoreInitialSystemStreams();
System.out.println(console);
}filter:可以对流中的元素进行条件过滤,符合过滤条件的才能继续留在流中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* filter
* <p>
*/
void testFilter() {
authors.stream()
.filter(author -> author.getName().length() == 3)
.forEach(author -> System.out.println(author.getName()));
String console = bout.toString();
Assertions.assertTrue(console.contains("梁羽生"));
restoreInitialSystemStreams();
System.out.println(console);
}map:对流中的元素进行计算或转换。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/**
* map
* <p>
* 1. 输出所有作家的名字
* 2. 对所有作家的年龄加10岁
*/
void testMap() {
authors.stream()
.map(Author::getName)// method reference
.forEach(System.out::println);// method reference
authors.stream()
.map(Author::getAge)// method reference
.map(age -> Integer.sum(age, 10))
.forEach(System.out::println);// method reference
String console = bout.toString();
Assertions.assertFalse(console.contains("社会,文学"));
Assertions.assertFalse(console.contains("35"));
restoreInitialSystemStreams();
System.out.println(console);
}distinct:去除流中的重复元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/**
* distinct
* <p>
* 输出所有作家的名字并去重
*/
void testDistinct() {
authors.stream()
.distinct()
.map(Author::getName)
.forEach(System.out::println);
String console = bout.toString();
Assertions.assertEquals(5, console.split(System.lineSeparator()).length);
restoreInitialSystemStreams();
System.out.println(console);
}sorted:对流中的元素进行排序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/**
* sorted
* <p>
* 升序输出所有作家的年龄并去重
*/
void testSorted() {
Assertions.assertThrows(ClassCastException.class, () -> {
authors.stream()
.sorted()// 无参sorted方法要求被排序对象实现java.lang.Comparable接口,否则将抛出类型转换异常
.forEach(author -> System.out.println(author.getName()));
});
authors.stream()
.distinct()
.map(Author::getAge)
.sorted(Comparator.comparingInt(Integer::intValue))// method reference
.forEach(System.out::println);// method reference
String console = bout.toString();
Assertions.assertEquals("30", console.split(System.lineSeparator())[0]);
restoreInitialSystemStreams();
System.out.println(console);
}limit:获取流中的前 N 个元素,截断操作,超出的部分被丢抛弃。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/**
* limit
* <p>
* 降序输出所有作家中年龄最大的两位作家的名字并去重
*/
void testLimit() {
authors.stream()
.distinct()
.sorted((a, b) -> b.getAge().compareTo(a.getAge()))
.map(Author::getName)
.limit(2)
.forEach(System.out::println);
String console = bout.toString();
Assertions.assertTrue(console.contains("金庸"));
Assertions.assertTrue(console.contains("卡尔·马克思"));
Assertions.assertFalse(console.contains("老舍"));
restoreInitialSystemStreams();
System.out.println(console);
}skip:跳过流中的前 N 个元素,返回剩下的元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* skip
* <p>
* 降序输出年龄最大以外的其他作家并去重
*/
void testSkip() {
authors.stream()
.distinct()
.sorted((a, b) -> b.getAge().compareTo(a.getAge()))
.map(Author::getName)
.skip(1)
.forEach(System.out::println);
String console = bout.toString();
Assertions.assertFalse(console.contains("金庸"));
Assertions.assertEquals(4, console.split(System.lineSeparator()).length);
restoreInitialSystemStreams();
System.out.println(console);
}flatMap:可以把一个对象转换成多个对象作为流中的元素。栗子1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* flatmap
* <p>
* 输出所有书籍的名字并去重
*/
void testFlatMap1() {
authors.stream()
.flatMap(author -> author.getBooks().stream())
.distinct()
.forEach(book -> System.out.println(book.getName()));
String console = bout.toString();
restoreInitialSystemStreams();
System.out.println(console);
}栗子2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/**
* flatmap
* <p>
* 输出所有书籍的分类并去重,不能出现逗号分隔的格式,如:小说,文学
*/
void testFlatMap2() {
authors.stream()
.distinct()// 对作家去重
.flatMap(author -> author.getBooks().stream())
.distinct()// 对书籍去重
.flatMap(book -> Arrays.stream(book.getCategory().split(",")))
.distinct()
.forEach(System.out::println);
String console = bout.toString();
Assertions.assertFalse(console.contains("小说,文学"));
Assertions.assertEquals(7, console.split(System.lineSeparator()).length);
restoreInitialSystemStreams();
System.out.println(console);
}
终结操作
流的中间操作总是是惰性的,若不调用终结操作将不会执行任何中间操作;下面的代码将不会输出任何作家的name,只会输出作家的id和age:
1 | /** |
输出如下:
1 | age.35 |
foreach
遍历流中的元素,前面大量的栗子中已有提及,此处不再进行代码赘述。
count
获取流中元素的个数。
1 | /** |
max
获取流中的最大值。
1 | /** |
min
获取流中的最小值。
1 | /** |
sum
对流中的数值求和,该方法仅在基础类型包装流中提供(IntStream,DoubleStream,LongStream)
1 | /** |
collect
收集流中的结果,对中间操作的结果进行聚合、分组、分区、拼接、转换(转换为Collection或Map等)。
转换
collect(Collector.toSet()):将中间操作的结果收集到HashSet中。1
2
3
4
5
6
7
8
9
10
11
12
13/**
* collect(Collectors.toSet())
* <p>
* 将所有作家的名字收集到Set中
*/
void testCollectCollectorsToSet() {
Set<String> set = authors.stream()
.map(Author::getName)
.collect(Collectors.toSet());// HashSet 实现 将去除所有重复项
Assertions.assertEquals(5, set.size());
}collect(Collectors.toList()):将中间操作的结果收集到ArrayList中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/**
* collect(Collectors.toList())
* <p>
* 将所有作家的名字收集到List中
*/
void testCollectCollectorsToList() {
List<String> namesList = authors.stream()
.distinct()
.map(Author::getName)
.distinct()
.collect(Collectors.toList());// ArrayList 实现 需要自行去重
Assertions.assertEquals(5, namesList.size());
}collect(Collectors.toCollection()):将中间操作的结果收集到Collection接口的实现类中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/**
* collect(Collectors.toCollection())
* <p>
* 将所有作家的名字收集到Collection的实现类中
*/
void testCollectCollectorsToCollection() {
Set<String> namesCollectionSet = authors.stream()
.map(Author::getName)
.collect(Collectors.toCollection(HashSet::new));// 利用HashSet去重 等价于 Collectors.toSet()
Assertions.assertEquals(5, namesCollectionSet.size());
List<String> namesCollectionList = authors.stream()
.distinct()
.map(Author::getName)
.distinct()
.collect(Collectors.toCollection(ArrayList::new));// 这种方式也需要自行去重 等价于 Collectors.toList()
Assertions.assertEquals(5, namesCollectionList.size());
}collect(Collectors.toMap()):将中间操作的结果收集到Map接口的实现类中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/**
* collect(Collectors.toMap())
* <p>
* 将所有作家收集为姓名-年龄的键值对Map
*/
void testCollectCollectorsToMap() {
/*若中间操作的结果存在重复项,此时收集为Map将抛出IllegalStateException*/
IllegalStateException ise = Assertions.assertThrows(IllegalStateException.class, () -> authors.stream()
.collect(Collectors.toMap(Author::getName, Author::getAge))
);
Assertions.assertTrue(ise.getMessage().contains("Duplicate key 49"));
/*先执行中间操作去重后再收集到Map中,避免IllegalStateException*/
Map<String, Integer> authorNameAgeMap1 = authors.stream()
.distinct()
.collect(Collectors.toMap(Author::getName, Author::getAge));
Assertions.assertEquals(5, authorNameAgeMap1.size());
/*或者自定义重复项的处理*/
Map<String, Integer> authorNameAgeMap2 = authors.stream()
.collect(Collectors.toConcurrentMap(Author::getName, Author::getAge, (i1, i2) -> i1));
Assertions.assertEquals(5, authorNameAgeMap2.size());
}collect(Collectors.toConcurrentMap()):将中间操作的结果收集到ConcurrentMap接口的实现类中,与collect(Collectors.toMap())类似。
聚合:对中间操作的结果进行最值、求和、均值、总数等聚合计算。
最值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/**
* collect(Collectors.maxBy()) 或 collect(Collectors.maxBy())
* <p>
* 求年龄最大的作家和评分最低的书籍
*/
void testCollectCollectorsMaxByMinBy() {
Optional<Author> maxAgeAuthorOptional = authors.stream()
.distinct()
.collect(Collectors.maxBy(Comparator.comparingInt(Author::getAge)));
maxAgeAuthorOptional.ifPresent(author -> Assertions.assertEquals("金庸", author.getName()));
Optional<Book> minScoreBookOptional = authors.stream()
.distinct()
.flatMap(author -> author.getBooks().stream())
.collect(Collectors.minBy(Comparator.comparingDouble(Book::getScore)));
minScoreBookOptional.ifPresent(book -> Assertions.assertEquals(57.81, book.getScore().doubleValue()));
}求和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/**
* collect(Collectors.summingDouble())
* <p>
* 求所有作家的所有书籍的总评分
*/
void testCollectCollectorsSummingDouble() {
Double sum = authors.stream()
.distinct()
.flatMap(author -> author.getBooks().stream())
.distinct()
.collect(Collectors.summingDouble(Book::getScore));// 同理还有 summingInt summingLong 方法
Assertions.assertEquals(1667.28, sum);
}均值
1
2
3
4
5
6
7
8
9
10
11
12
13
14/**
* collect(Collectors.averagingInt())
* <p>
* 求所有作家的平均年龄
*/
void testCollectCollectorsAveragingInt() {
Double average = authors.stream()
.distinct()
.map(Author::getAge)
.collect(Collectors.averagingInt(age -> age));// 类似还有 averagingDouble AveragingLong 方法
Assertions.assertEquals(53.6, average);
}总数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/**
* collect(Collectors.counting())
* <p>
* 求作家的数量和作家的书籍数量
*/
void testCollectCollectorsCounting() {
Long counting1 = authors.stream()
.distinct()
.flatMap(author -> author.getBooks().stream())
.distinct()
.collect(Collectors.counting());
Assertions.assertEquals(20, counting1);
Long counting2 = authors.stream()
.distinct()
.collect(Collectors.counting());
Assertions.assertEquals(5, counting2);
}
分组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60/**
* collect(Collectors.groupingBy())
* <p>
* 进行简单或多级分组
*/
void testCollectCollectorsGroupingBy() {
/*简单分组
*
* 将所有作家按照年龄进行分组,60岁以上老年作家,40岁以上中年作家,40岁以下青年作家
* */
Map<String, List<Author>> map1 = authors.stream()
.distinct()
.collect(Collectors.groupingBy(author -> {
Integer age = author.getAge();
if (age >= 60) {
return "老年作家";
} else if (age >= 40) {
return "中年作家";
} else {
return "青年作家";
}
}));
Assertions.assertEquals(3, map1.size());
/*多级分组
*
* 一级分组为分类,二级分组为评级
* */
Map<String, Map<String, List<Book>>> map2 = authors.stream()
.distinct()
.flatMap(author -> author.getBooks().stream())
.distinct()
.collect(Collectors.groupingBy(Book::getCategory, Collectors.groupingBy(book -> {
Double score = book.getScore();
if (score > 85) {
return "神作";
} else if (score > 60) {
return "佳作";
} else {
return "垃圾";
}
})));
Assertions.assertEquals(7, map2.size());
Map<String, List<Book>> economicCategoryMap = map2.getOrDefault("经济", new HashMap<>());
Assertions.assertEquals(1, economicCategoryMap.size());
List<Book> economicMastery = economicCategoryMap.getOrDefault("神作", new ArrayList<>());
Assertions.assertEquals(1, economicMastery.size());
restoreInitialSystemStreams();
System.out.println(economicCategoryMap);
}输出如下:
1
{神作=[Book(id=16, name=剩余价值理论, score=85.31, category=经济, introduction=马克思的剩余价值理论是在批判地继承古典政治终济学的研究成果和他所创立的科学的劳动价值理论的基础上,经过长期的考察和研究逐步建立起来的。)]}
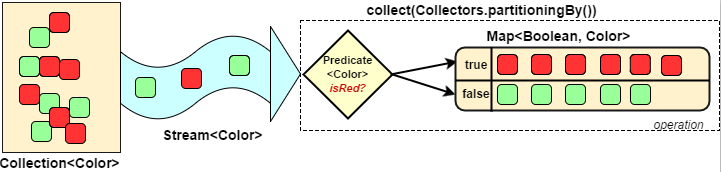
分区:

1
2
3
4
5
6
7
8
9
10
11
12
13/**
* collect(Collectors.partitioningBy())
* <p>
* 根据值断言结果的布尔值,把集合分割为两个列表,一个true列表,一个false列表。
*/
void testCollectCollectorsPartitioningBy() {
Map<Boolean, List<Author>> map = authors.stream()
.distinct()
.collect(Collectors.partitioningBy(author -> author.getAge() > 60));
Assertions.assertEquals(2, map.size());
}拼接:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/**
* collect(Collectors.joining())
* <p>
* 收集流中的结果并进行字符串拼接
*/
void testCollectCollectorsJoining() {
String authorNamesWithComma = authors.stream()
.distinct()
.map(Author::getName)
.collect(Collectors.joining(","));
String authorNamesWithCommaAndSquareBracket = authors.stream()
.distinct()
.map(Author::getName)
.collect(Collectors.joining(",", "[", "]"));
System.out.println(authorNamesWithComma);
Assertions.assertEquals(5, bout.toString().split(",").length);
bout.reset();
System.out.println(authorNamesWithCommaAndSquareBracket);
Assertions.assertTrue(bout.toString().startsWith("["));
restoreInitialSystemStreams();
System.out.println(authorNamesWithComma);
System.out.println(authorNamesWithCommaAndSquareBracket);
}
*Match
以Match结尾的相关终结方法提供了匹配相关的操作。
anyMatch:匹配流中是否有任意满足条件的元素。1
2
3
4
5
6
7
8
9
10
11
12
13/**
* anyMatch
* <p>
* 判断是否有年龄在70岁以上的作家
*/
void testAnyMatch() {
boolean b = authors.stream()
.distinct()
.anyMatch(author -> author.getAge() > 70);
Assertions.assertTrue(b);
}allMatch:匹配流中的所有元素是否满足给定条件。1
2
3
4
5
6
7
8
9
10
11
12
13/**
* allMatch
* <p>
* 判断所有作家是否都是成年人
*/
void testAllMatch() {
boolean b = authors.stream()
.distinct()
.allMatch(author -> author.getAge() > 18);
Assertions.assertTrue(b);
}noneMatch:流中的所有元素是否均不满足给定讲条件。1
2
3
4
5
6
7
8
9
10
11
12
13/**
* noneMatch
* <p>
* 判断所有作家都没有超过100岁的人
*/
void testNoneMatch() {
boolean b = authors.stream()
.distinct()
.noneMatch(author -> author.getAge() > 100);
Assertions.assertTrue(b);
}
find*
以find开头的终结方法提供了查找相关的操作。
findAny:获取流中任意一个满足条件的元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14/**
* findAny
* <p>
* 获取任意一个年龄大于18的作家,如果存在就输出他的名字
*/
void testFindAny() {
authors.stream()
.distinct()
.filter(author -> author.getAge() > 18)
.findAny().ifPresent(System.out::println);
Assertions.assertEquals(1, bout.toString().split(System.lineSeparator()).length);
}findFirst:获取流中的第一个元素。1
2
3
4
5
6
7
8
9
10
11
12
13/**
* findFirst
* <p>
* 获取年龄最小的作家并输出他的名字
*/
void testFindFirst() {
authors.stream()
.sorted(Comparator.comparingInt(Author::getAge))
.findFirst().ifPresent(author -> System.out.println(author.getName()));// can be implemented by min()
Assertions.assertTrue(bout.toString().contains("老舍"));
}
reduce
reduce方法顾名思义,该单词的含义为减少、缩减,可以通俗的理解为归并。
该方法的文档注释阐明了它等同于如下代码:
1 | T result = identity; |
reduce的作用是把 Stream 中的元素给组合起来;
可以传入一个初始值,它会按照定义好的计算方式依次将流中的元素和初始化值进行计算并得出结果,再依次与后面的元素计算。
1 | /** |
工具调试
idea trace current stream
中间短路操作可以提前结束